

Analysing collated data
Protecting patients with mathematics
Patient files might contain hints for detecting diseases at an early stage. But how can the collated data be evaluated without invading the patients’ privacy? With the help of mathematics.
Self-learning computer programmes can trawl through large data volumes and detect regularities. Such programmes are deployed, for example, in modern spam filters: by monitoring which emails are labelled as spam by the users, they learn what constitutes spam emails, even though the characteristic features of such emails had never been explicitly specified.
Machine learning does not only help improve spam filters, but it is also useful wherever large databases have to be checked for patterns, for example in searching engines, automated speech recognition and in the analysis of medical data. In case of the latter, algorithms are capable of detecting links in a batch of patient files and of identifying criteria for an early diagnosis of diseases.
“It is imperative to ensure that each individual patient’s privacy is protected throughout,” warns Prof Dr Hans Simon from the Chair of Theoretical Computer Science. Together with PhD students Francesco Alda and Filipp Valovich, he investigates in what way sensitive data may be statistically evaluated without revealing the anonymity of the individuals involved.

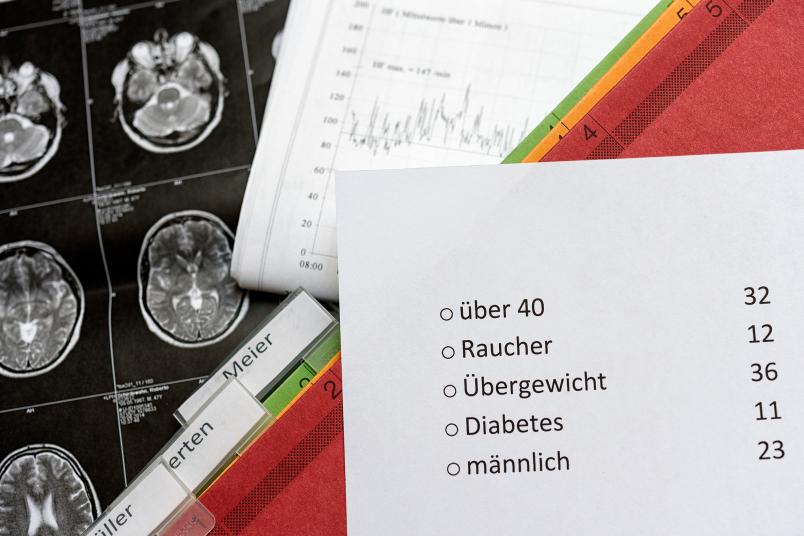
The mathematicians are specifically analysing a form of machine learning which is limited to so-called count requests. This works as follows: if an algorithm is meant to evaluate a patient database, it is only permitted to ask Yes/No questions and to count in how many cases the answer is “Yes”.
Admissible questions include: Does the person smoke? Is the person male? Does the person weigh more than 80 kilograms? If a learning algorithm sends these questions to a patient database, it receives three numbers in reply: the number of smokers, the number of men, and the number of patients heavier than 80 kilograms.
Distorting patient data
The principle of count requests sounds anonymous – the result is merely a statistical summary, after all. Nevertheless, it is possible to attain information about individual patients. Hans Simon and his colleagues are therefore investigating mechanisms such as “Randomized Response Schemes”, which are designed to protect patient privacy.
Here, patient data are distorted, i.e. they are randomly modified. In simple terms: it is as if dice were cast for each patient and the numbers on the dice were added to the values provided in the file. The process alters individual patient data significantly and unpredictably. However, in the best-case scenario, it does not affect the statistical summaries to any greater extent than the statistical random fluctuation that is present in the data in any case.
Anonymous – what does this mean?
In order to approximate the best-case scenario, the distortion has to meet certain requirements. “The challenge we face is to identify such requirements and to formulate them in unmistakable terms,” explains Hans Simon. “Consequently, we are looking for requirements for random distortion that ensure, on the one hand, that the individual data are so strongly altered that respective patients can no longer be identified while, on the other hand, the responses sent back to the learning algorithms from the modified database do not deviate much from those of the original database.“
What is so easy to describe in one sentence means in practice that mathematicians have to perform detailed, complex thought processes. First, they have to precisely define the relevant terms: what, exactly, does it mean that patients “remain anonymous”? What, exactly, does it mean that the responses to the learning algorithms are “similar”?
Subsequently, they look for requirements from which it can be derived that the distortion does anonymise patient data, but does not substantially alter statistical summaries.
Identifying individual patients in the database
The mathematicians working with Hans Simon have therefore looked into “Differential Privacy”. Developed by US-American computer engineer Cynthia Dwork, the concept provides an answer to the question what anonymity may mean in strictly mathematical terms: Differential Privacy is a standard for measuring how precisely an individual patient may be identified in a database. It works on the assumption that there is a concrete count request and two databases A and B, which differ in terms of only one patient. The random distortion meets the Differential Privacy standard if it doesn’t really matter whether a request had been submitted to database A or database B; that means if the likelihood of a specific cumulative response to the count request is similar in both cases.
“Accordingly, the total result of the request does not depend on an individual patient so much,” explains Hans Simon. He and his colleagues also use exact definitions in order to precisely determine in mathematical terms what it means that the distorted data yield statistical conclusions similar to those of the original data; this is termed Accuracy.
Representing data as vectors
For the distortion of data, Hans Simon’s team wishes to comply with both requirements, i.e. ensure Differential Privacy as well as Accuracy. To this end, the researchers have used a trick: they have identified a connection to another mathematical subject, namely the so-called linear arrangements. They have translated the problem there.
The researchers represent each individual patient file and each admissible count request as a vector, i.e. as an arrow in a geometric space. A Yes response exists when the arrows of patient file and count request form a sharp angle. A No response exists when the arrows form an obtuse angle.
Distorting vectors instead of original data
As a result, the distortion is no longer performed in the original patient data, but in the corresponding arrows. Hans Simon and his team have proved that the distortion works very well when this process is used, i.e. both Differential Privacy and Accuracy are complied with. The requirement is that the sharp angles are indeed sharp, namely significantly smaller than 90 degrees, and that the obtuse angles are indeed obtuse, namely significantly greater than 90 degrees.
The mathematicians from Bochum have accomplished their first intermediate objective, and they intend to expand their research results. “Translating patient data and algorithm requests into the geometric space is a major hurdle,” deplores Hans Simon. “A generic formula does not exist. Moreover, we know there are some database types that are not suited for geometric representation.”

It would be great if real data could be replaced by synthetic data
Hans Simon
Hans Simon has a vision that harks back to an idea of US-American researcher Avrim Blum: “It would be great if real data could be replaced by synthetic data, which would provide no information whatsoever about the patients, but which would yield the same statistical conclusions.”
Such synthetic data could be made available to the general public without any restrictions. “Based on the current results, gathered by the research community, we know that this ideal objective remains unattainable,” says Hans Simon. It might, however, become a driving force necessary to generate vital results between the poles of statistical data analysis and privacy.
