
Neuroinformatik
Modelle hüpfen lassen
Maschinen kann man beibringen, Krebs zuverlässig zu erkennen. Nun braucht es noch Methoden, um den Datenschutz zu gewährleisten. Bochumer Forschende haben bereits eine Idee, wie das gelingen kann.
Computer, erkennst du auf dem Thorax-Scan ein Karzinom? Zeig mir alle Patienten, die einen ähnlichen Befund aufweisen! Was futuristisch klingt, gehört in vielen smarten Krankenhäusern bereits zum Arbeitsalltag. Blitzschnell klicken sich heute Ärztinnen und Ärzte durch Datenbanken, stellen Diagnosen oder gleichen Scans ab – dank Vorstufen von Künstlicher Intelligenz (KI). Doch können diese Systeme auch schon automatisch Krebs entdecken? „Die modernsten neuronalen Netze sind wirklich gut. Sie können zuverlässiger Krebs erkennen als Ärztinnen und Ärzte“, weiß Dr. Michael Kamp vom RUB-Institut für Neuroinformatik. In Kooperation mit dem Institut für Künstliche Intelligenz in der Medizin (IKIM) des Uniklinikums Essens untersucht Kamp, wie sich künstliche Intelligenzsysteme mit Methoden des maschinellen Lernens, insbesondere des Deep Learnings, für den sensiblen Bereich der Medizin trainieren lassen.

Die besondere Lerntechnik, auf die sich Kamps Forschungsgruppe Trustworthy Machine Learning dabei spezialisiert hat und deren Anwendung sie weiter optimieren will, nennt sich föderiertes Lernen. Sie ist besonders gut geeignet, um den hohen Anforderungen, die die Medizin an die KI stellt, gerecht zu werden.
Maschinelles Lernen
„Nehmen wir an, ein Krankenhaus hat Bilder von 50 Patienten mit einer bestimmten Ausprägung von Krebs und ein anderes 40 Scans von anderen Patienten. Aus Datenschutzgründen ist das Versenden der sensitiven Patientendaten selbstverständlich untersagt. Um jedoch neuronale Netze zu trainieren, brauchen wir alle diese Daten an einem Ort“, beschreibt Kamp die Herausforderung, vor der sein Team steht. Wie können vertrauliche Daten, die das Krankenhaus nicht verlassen dürfen, trotzdem nutzbar gemacht werden? Hier setzt die Technik des föderierten Lernens an.
Föderiertes Lernen
„Beim föderierten Lernen trainiere ich zunächst dezentral in jedem Krankenhaus jeweils ein Modell mit den lokal verfügbaren Daten, bis das dortige neuronale Netz so gut ist, dass es eine bestimmte Krebsart erkennen kann“, erklärt Kamp. Wie sieht das Training konkret aus? Wie bringt man Maschinen die Erkennung von Krebs bei? „Der Computer lernt aus Bildern, etwa CT-Scans, ein Muster oder eine Regel abzuleiten. Dazu löst er die einzelnen Bildpixel in Daten auf und berechnet dann mit einer mathematischen Formel ein Ergebnis. Dieses gleicht er anschließend mit der Beschriftung des Scans ab. Das macht er viele Tausend, häufig Millionen Mal, bis er relativ verlässlich vorhersagen kann, ob ein Scan ein Karzinom zeigt oder nicht“, erklärt Kamp.
Modelle auf Reisen schicken
Das abstrahierte Modell, das nach den Trainings an einem Krankenhaus entstanden ist, kann dann verschickt werden an das nächste Krankenhaus. „Die grundsätzliche Architektur der Modelle ist überall gleich, weil das zugrunde liegende Problem – die Erkennung einer bestimmten Krebsart – das gleiche ist“, erläutert Kamp. Die Daten der Patientinnen und Patienten bleiben vor Ort zurück; nur die Muster gehen auf Reise. In der nächsten Klinik oder Praxis wiederholt sich der Lernprozess mit neuen Scans. Mit je mehr Daten das Netz gefüttert wird, desto besser kann es später unterscheiden und auswerten. Der Vorteil der Lerntechnik: Die Krankenhäuser nähren das Modell, ohne ihre Daten zu verschicken. Schickt man viele Modelle gleichzeitig auf Reise, werden diese nach einiger Zeit zusammengebracht und zu einem besonders guten Modell zusammengefasst.
Wissenschaftsmagazin Rubin kostenlos abonnieren
Vorteile für kleinere Praxen
Das Team um Michael Kamp hat dabei herausgefunden, dass die Technik des föderierten Lernens auch dann funktionieren kann, wenn ein Modell sich zunächst nur aus wenigen Daten, etwa acht Bildern pro Krankenhaus, speist. Damit man am Ende auch dann noch ein verlässliches End-Modell erhält, muss das lokale Modell mehrere Runden von Krankenhaus zu Krankenhaus drehen, bevor man es mit anderen zu einem globalen Modell vereint. „Nur wenn ein einzelnes Modell zehn Mal gehüpft ist, bekommt man auch am Ende ein aggregiertes Modell, auf das Verlass ist“, fasst Kamp den aktuellen Forschungsstand zu dieser erweiterten Form des föderierten Lernens zusammen.
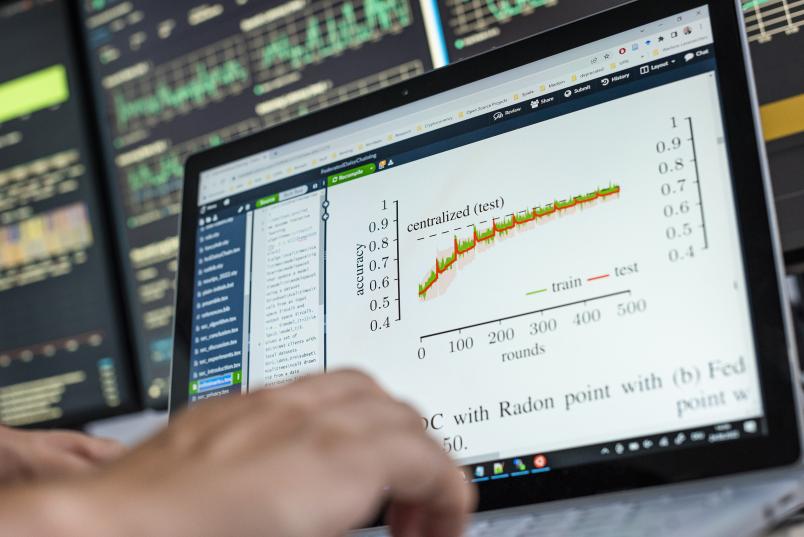
Künftig, so die Hoffnung der Forschenden, könnten auf diese Weise auch kleine Praxen oder Krankenhäuser in abgelegenen Gegenden am föderierten Lernen teilnehmen und so vom Datenschatz größerer Kliniken profitieren, ohne dass dabei die Daten die Standorte verlassen. Das erweiterte föderierte Lernen scheint für die Anwendung der KI im Medizin-Kontext viele Vorteile mit sich zu bringen. Doch die gebauten Netze und Modelle werfen auch Fragen auf, etwa zur Qualität, Privatsphäre und Praxistauglichkeit. Diesen widmen sich Kamp und sein Team in verschieden Teilprojekten.
Grundlagen verstehen
Zum einen möchten die RUB-Informatikerinnen und -Informatiker ergründen, wie man eine gute Modellqualität der neuronalen Netze gewährleisten kann. „Wir fragen uns: Wie können wir garantieren, dass unsere neuronalen Netze auch qualitativ gut sind, die Aussagen am Ende richtig? Können wir Wahrscheinlichkeiten angeben oder Unsicherheiten vorhersagen?“, so Kamp. Dazu tauchen die Forschenden tief in die Grundlagen der Lerntheorie ein. Sie untersuchen, welche Eigenschaften die Daten haben müssen, mit denen die Modelle gefüttert werden und wie sich diese messen lassen. „Die Herausforderung und die Kernfrage der Lerntheorie ist es, den Generalisierungsfehler, also den Unterschied zwischen dem Fehler, den das Modell auf den vorhandenen Daten macht, und dem Fehler, den das Modell auf neuen, unbekannten Daten macht, klein zu halten“, so Kamp.
Vertraulichkeit wahren
Neben der grundlegenden Lerntechnik möchten die Forschenden auch die Praxistauglichkeit der neuronalen Netze weiter optimieren. So wollen Kamp und sein Team sicherstellen, dass die vertraulichen Patientendaten tatsächlich geschützt sind, wenn Modelle von Krankenhaus zu Krankenhaus verschickt werden. „Zusammenhänge zwischen den Modellen und Daten dürfen nicht entdeckbar oder rekonstruierbar sein. Sie dürfen keine Rückschlüsse zulassen“, betont Kamp.

Es ist eine Herausforderung, den sweet spot zwischen einem Zuviel und Zuwenig an Informationen zu finden.
Michael Kamp
Ein weiteres Projektteam arbeitet daran, die fertigen Netze oder Assistenzsysteme nutzbar und bedienbar für das Klinikpersonal zu machen. „Sie müssen am Ende für Ärztinnen und Ärzte zu interpretieren sein“, so Kamp. „Neuronale Netze sind komplex, und es ist eine Herausforderung, den sweet spot zwischen einem Zuviel und Zuwenig an Informationen zu finden“, sagt Kamp. Im besten Fall sprechen die Systeme Empfehlungen aus und liefern qualitativ hochwertige Erklärungen und Begründungen direkt mit.

Schon in wenigen Jahren werden künstliche Systeme dem Personal in Kliniken noch weitreichender assistieren können. Vielleicht wird man mit Assistenzsystemen auch Problemen entgegenwirken können, wie etwa dem Personalmangel im ländlichen Raum. Und dennoch, so ist sich Kamp sicher, wird der Beruf des Arztes oder der Ärztin unersetzbar bleiben: „Es wird immer Menschen brauchen, die die Diagnose eines Assistenzprogramms bestätigen. Wir bauen hier keine Gehirne nach, sondern lösen ein mathematisches Optimierungsproblem.“







